

This case study is about the search for a personal data anonymization software.
Client’s problem statement
Client is a French group of publishing companies, subsidiary of a large conglomerate. It is the second-largest French publishing group. They are looking for an anonymization solution of personal data for their corporate non-production environnements. Their IT gathers a large SAP scope (On-Premise & On Cloud) but also many others different systems that may need to be anonymized.
They have 3 main KPIs:
KPI#1: Efficiency, easy to use, Anonymizer tool that can run on SAP and Non-SAP Systems
KPI#3 : Compatibility with both premises and cloud solutions
KPI#2 : High ROI (Sensitive to cost)
List of relevant vendors
Informatica, Delphix, Talend, SAP UI Masking, IBM Optim, Snowflake, DataProf, Baffle, EPI-USE Labs, Alteryix, Oracle, Open Text, Fortanix, Mentis, Genrocket., Arcad Software, Privitar, Tonic.AI, VGS, Precisely, Libelle, Gretel.ai, Imperva, OneTrust, KNIME, K2view, Brighter AI Technologies, Tumult Labs, PrivacyOne, Protegrity, Droon
In just 3 weeks, Vektiq AI-powered platform pinpointed the ideal personal data anonymization software for a RSSI.
Ready to start your search? Link to our self-service platform here.
Performance Matrix
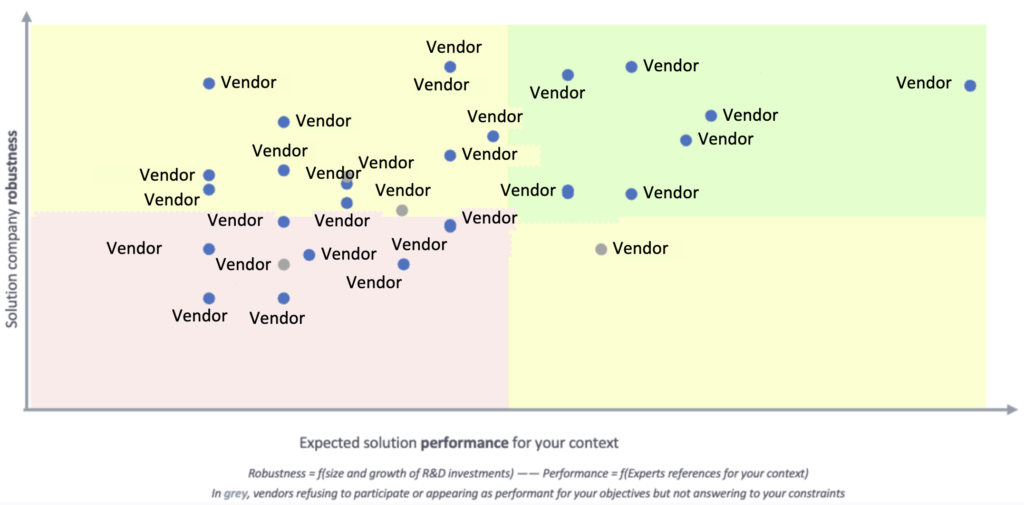
Vendor’s answers
Informatica’s answer
Informatica provides its customers with various tools and features to help them with data anonymization, ensuring compliance with data protection regulations and safeguarding sensitive information. Here’s how Informatica helps its customers with data anonymization:
Data Masking
Sensitive Data Discovery
Data Subsetting and Sampling
Referential Integrity Preservation
Encryption
Policy Management and Governance
Audit and Compliance Reporting
Automated Anonymization
What other vendors say about Informatica
Vs Talend: license cost, ease of use (possibility to enable business users)
Vs Imperva:
– Automated operations
-Retain realistic data attributes for test integrity
-Avoid negative compliance and security impact of
– breaches and audit failures
Vs OneTrust:
-Automated Regulatory Intelligence
-Field Level Discovery Classification
-Automated remediation actions (anonymisation, deletion, redaction masking, etc.)
Vs Precisely: Our pricing model is more simple.
Vs Delphix: Delphix est une solution Low code to no Code ce qui permet une intégration simplifiée dans le système d’information du client. Découverte automatisée des données à caractère personnelle. Delphix permet nativement d’avoir une intégrité référentielle multi-coud et entre plusieurs applications. Performance: avec l’architecture Hyperscale sur base de containers, Delphix permet d’anonymiser des volumes très important de données ( + de 10TB ou plusieurs de 100 aines de millions de lignes) en un temps court.
Vs Alteryx:
Informatica and Alteryx play in different markets.
-The need for curated/trusted data makes Alteryx users more successful within organizations . Alteryx is a complement to your data integration strategy
-Alteryx can make your data integration strategy better. Even in the context of a strong data integration strategy, allowing business and IT to work closely together on the same platform helps organizations unlock value from their data, faster.
-Alteryx is a platform for solving analytical problems, data analysis is not decoupled from data preparation.
-Alteryx is a perfect complement as we overcome the limitations of traditional data integration vendors with:
– Agility: time to value for IT who can use Alteryx to prototype data integration flows and time to insight for the business who can answer any ad-hoc requests, experiment and solve problems.
– Accessibility / self-service: Alteryx offers a platform that can be used by all users, not just IT, especially by business users who best know the data and can help IT build the right workflows.
-Analytics, not just data preparation
Vs GenRocket:
Traditional TDM vendors such as Informatica use a Gold Copy approaches for test data that has many drawbacks:
-The test data only meets 50% of requirements for volume, variety and formats so organizations have to also manually create test data (spreadsheets, scripts, batch runs)
-Test data reservation is required because there isn’t enough tests data for different testing teams
-Test data storage is expensive (all those terabytes of Gold Copy data)
-Test data goes “stale” quickly and refresh cycles for Gold Copy data in regulated businesses can take days to weeks
-Test data is not easily mapped into a test case as part of a CI/CD pipeline
-Test data use isn’t easily tracked so test data CoE teams lack visibility into ROI
In contrast, GenRocket’s approach for test data automation has many advantages:
-Test data meets close to 100% of test data requirements with no manual data creation
-Test data does not need to be reserved; all testing teams get as much data volume and variety as they need
-Test data does not have to be stored; it is delivered “on demand” in seconds to minutes
-Test data does not go stale because it is dynamically updated, always accurate and always “fresh”
-Test data is mapped directly into a test case, called by the test script as part of a CI/CD pipeline
-Test data use is automatically tracked so test data CoE teams have full visibility into ROI
Delphix’s answer
La plateforme de données Delphix permet d’automatiser la chaîne de distribution de données anonymisées dans les environnements de non-production (Développeurs, QA, analystes..) ainsi que la découverte et la protection des données sensibles dans le respect des réglementations en vigueur (RGPD). Les clients accélèrent ainsi la modernisation de leurs applications tout en réduisant les risques de conformité.
La plateforme est composée de deux solutions principales:
Continuous Data Engine: une plate-forme qui fournit des copies virtuelles légères de bases de données pour les cas d’utilisation de développement/test, de reporting, d’IA/ML et de support de production. Grâce à cette virtualisation, nous pouvons fournir et actualiser des bases de données de grande volumétries (10 To+) en quelques minutes, sans avoir besoin de faire de subsetting ou d’utiliser des données synthétiques.
Avantages du Continuous Data : Consolidation 10:1 des environnements hors-production, Synchronisation sans interruption avec la base de production, Provisionnement rapide, Contrôle de versions de données, Granularité transactionnelle, Multi-Cloud, Intégration CI/CD, Plateforme full API ,Portail de Self-Service
Continuous Compliance: solution d’anonymisation permettant la sécurisation et l’automatisation de la gouvernance autour des données sensibles en veillant à ce que vos données soient en conformité avec les réglementations en vigueur et votre politique interne. Avantages du Continuous Compliance :Profilage automatique des données sensibles, Algorithmes couvrant 98% des cas clients (low to zero code), Anonymisation automatique, Intégrité référentielle multi-cloud sur plusieurs bases et applications, Anonymisation de PB de données en un temps record
What others think of Delphix:
Vs Mantis: Offers rudimentary masking methods like substitution, redaction, tokenization etc. Mage on the other hand offers over 80+ anonymization methods from encryption, masking, tokenization and masking. Unlike Delphix, Mage anonymization can ensure referential integrity across data sources while maintaining data usability and function without compromising data security.
Vs Tonic.AI: Tonic provides more realistic data, preserving the messiness and the noise of the original dataset. Delphix provides standard masking.
Vs Imperva: Easy to deploy simple to use, not dependent on a specific platform
Vs GenRocket: Traditional TDM vendors like Delphix leverage a Gold Copy approach for test data that has many drawbacks:
The test data only meets 50% of requirements for volume, variety and formats so organizations have to also manually create test data (spreadsheets, scripts, batch runs)
-Test data reservation is required because there isn’t enough tests data for different testing teams
-Test data storage is expensive (all those terabytes of Gold Copy data)
-Test data goes “stale” quickly and refresh cycles for Gold Copy data in regulated businesses can take days to weeks
-Test data is not easily mapped into a test case as part of a CI/CD pipeline
-Test data use isn’t easily tracked so test data CoE teams lack visibility into ROI
In contrast, GenRocket’s approach for test data automation has many advantages:
-Test data meets close to 100% of test data requirements with no manual data creation
-Test data does not need to be reserved; all testing teams get as much data volume and variety as they need
-Test data does not have to be stored; it is delivered “on demand” in seconds to minutes
-Test data does not go stale because it is dynamically updated, always accurate and always “fresh”
-Test data is mapped directly into a test case, called by the test script as part of a CI/CD pipeline
-Test data use is automatically tracked so test data CoE teams have full visibility into ROI
Talend’s answer
Our Data Masking and pseudonimyzation features are embedded in our Data Management platform that has multiple connectivity options to SAP and to many other data sources (databases, files, Cobol, cloud storage, APIs…). Talend Data Masking features provide built-in and extensible masking policies to intelligently de-identify sensitive data without losing referential integrity to meet regulatory/security/privacy requirements. It can mask, encrypt, shuffle or cleanse data through standard components. Its hybrid architecture allows processing on-premise, in your VPC or in the cloud. It is used by customers with stringent data security guidelines, for example in the Financial, Pharmaceutical and Defense. Talend also has a Data Catalog solution in his portfolio, enabling PII detection and usage tracking. Our pricing is independant of the volume of data or connections, it is based on the number of users, giving our customers greater visibility on the TCO of the solution.
What others think of Talend
Vs Informatica:
-Robustness and Scalability: Informatica has much more advanced algorythms, boosted in particular by AI, and continues to innovate and invest in the data anonymisation segment (it is in the process of acquiring a major player in the sector).
-Broad Connectivity: Informatica offers a wide range of pre-built connectors and adapters to connect to various data sources, applications, and cloud platforms. This extensive connectivity makes it easier to integrate with different systems and data types.
-Strong Customer Base
Vs Alteryx:
– Analytic for All, end-to-end & self-service Analytics Platform
– User Experience, Best-in-class ease of use
– Easy offer, easy deployment (pricing)
– Data Prep for Business users
– Alteryx Intelligence Suite for Citizen Data Scientist
– Descriptive, Diagnostic, Predictive & Prescriptive analytics
– Insight Generation, Specialized Analytics, Root-Cause analysis
– Low code – No code approach
Talend Open Studio is not for business analysts with a problem to solve, but rather for data engineers / IT. Alteryx and Talend remain fundamentally different and complementary. Although our data preparation capabilities can be used centrally by IT, our product was built for the business analyst, which makes it much easier to use.Alteryx Designer is at the core of our platform and contains a wide range of data manipulation capabilities to meet the most sophisticated needs – in one single product. This makes it very accessible, in comparison to Talend’s 15 different products with overlapping capabilities.
IBM’s answer
IBM’s data masking solutions utilize advanced techniques like tokenization, encryption, and randomization to protect sensitive data without compromising its usability for testing and development purposes.
You can also benefit from IBM’s broader portfolio of services, such as cloud solutions, AI-powered analytics, and cybersecurity, to further enhance their data protection and overall IT infrastructure.
IBM ongoing support and maintenance ensure that the data masking solution stays up-to-date with evolving security threats and changing business requirements.
Overall, partnering with IBM for data masking in SAP environments (connectors available both onprem and Cloud) comes with a trusted and experienced integrator, a tailor-made solution, and a commitment to data security and compliance, contributing to your success in securely managing sensitive information.
The solutions that could help you based on the use case : IBM Knowledge Catalog on Cloud Pak for Data (business-ready data for AI and analytics with intelligent cataloging, backed by active metadata and policy management)
https://www.ibm.com/products/knowledge-catalog
https://www.ibm.com/products/cloud-pak-for-data
IBM Security Guardium (Wide visibility, compliance and protection throughout the data security lifecycle)
What others think of IBM
Vs Talend: Cost, user interface
Vs Delphix: Simplicité de mise en oeuvre. Delphix est une solution Low code to no Code ce qui permet une intégration simplifiée dans le système d’information du client. Découverte automatisée des données à caractère personnelle. Delphix permet nativement d’avoir une intégrité référentielle multi-coud et entre plusieurs applications. Performance: avec l’architecture Hyperscale sur base de containers, Delphix permet d’anonymiser des volumes très important de données ( + de 10TB ou plusieurs de 100 aines de millions de lignes) en un temps court.
Vs Libelle: From our understanding, complaints about usability
What other vendors think of SAP
Vs Protegrity: SAP can only provide some access control and identity management in their systems. You would not have the ability to anonymize or pseudonymize data or initiate multi layered protection. This approach would not adhere to regulations and guidelines
Vs EPI-USE Labs: Data Secure offers a comprehensive and customizable solution to address the requirement for masking sensitive data. A significant competitive advantage over SAP lies in our provision of both dictionary and database masking capabilities. While SAP solely offers dictionary masking (UI masking only), sensitive data remains visible on the database, but with Data Secure, such risks are mitigated, ensuring enhanced data security and compliance. EPI-USE Labs provide a tool that allows masking sensitive data at dictionary and data base levels. Our solution is optimized for mass processing, all functional dependencies are automatically addressed, we provide an accelerated implementation with delivered content, EPI-USE Labs can customize any scrambling rule for Publishing company purposes in both dictionary and data base levels, the masking rules will work after systems upgrades or support packs, we are able to anonymize data across SAP and non-SAP systems and it secures support compliance with data privacy regulations.
Vs Delphix: SAP UI est dédié à SAP et ne supporte pas d’autres solutions. Delphix permet d’anonymiser de manière cohérente plusieurs technologies de bases et de fichiers différentes (SAP, Oracles, XML, SAP Hana, SQL Serveur….).
Vs Libelle: Only offers pseudonymization
Vs Snowflake: While SAP BW offers robust solutions, particularly for existing SAP customers, Snowflake provides several distinct advantages:
-Cloud-Native Architecture: Snowflake’s cloud-native architecture offers easy scalability and cost-effectiveness. SAP BW, on the other hand, was originally designed as an on-premise solution and might not deliver the same level of performance and cost-effectiveness in the cloud as Snowflake
-Easier Integration with Non-SAP Data Sources: While SAP BW integrates well with other SAP products, integration with non-SAP data sources can sometimes be complex. Snowflake, however, is designed to work seamlessly with a wide array of data sources, making it a more flexible solution when dealing with diverse data ecosystems.
-Separation of Storage and Compute: Snowflake’s architecture allows compute and storage resources to scale independently. This is different from SAP BW where scaling usually means scaling both, which can be less cost-effective.
-Simplified Pricing Model: Snowflake’s pricing is clear and predictable, based on storage and compute usage. SAP BW’s pricing can be more complex, depending on various factors including the number of users and the size of the organization.
-Support for Semi-Structured Data: Snowflake can handle structured and semi-structured data types, like JSON, XML, Avro, and Parquet natively. While SAP BW also supports various data types, dealing with semi-structured data typically requires additional steps or tools.
-Fully-Managed Service: Snowflake takes care of all maintenance, infrastructure management, and optimization tasks. In comparison, SAP BW might require more in-house maintenance, particularly in on-premise deployments.
Snowflake’s answer
Below, we’ll break down how Snowflake can solve Publishing company’s specific challenges in alignment with the stated KPIs:
KPI#1: Efficiency, Easy to Use, Anonymizer Tool for SAP and Non-SAP Systems à Solution with Snowflake:
-Dynamic Data Masking: Snowflake’s dynamic data masking feature allows Publishing company to apply specific policies that can mask or hide sensitive information. The raw data remains unchanged, ensuring the integrity of the information while maintaining privacy.
-Integration with SAP and Non-SAP Systems: Snowflake’s ability to connect with various data sources ensures a seamless integration process with both SAP and non-SAP environments.
-User-Friendly Interface: Snowflake’s platform is designed with ease of use in mind, allowing Publishing company’s team to execute and manage anonymization tasks without deep technical expertise.
KPI#3: Compatibility with Both Premises and Cloud Solutions à Solution with Snowflake:
-Hybrid Architecture Support: Snowflake’s flexibility in supporting both on-premise and cloud platforms will enable Publishing company to deploy the solution across their diverse IT environment.
-Real-Time Data Sharing: The platform facilitates secure data sharing across different regions and platforms, ensuring cohesion between different parts of Publishing company’s organization.
KPI#2: High ROI (Sensitive to Cost) à Solution with Snowflake:
-Pay-as-You-Go Model: Snowflake’s consumption-based pricing allows Publishing company to pay only for the storage and compute resources they use, avoiding unnecessary costs.
-Scalability: Snowflake can effortlessly scale up or down based on Publishing company’s needs, ensuring that they are neither overpaying for unnecessary resources nor constrained by lack of capacity.
-Risk Mitigation: By implementing a robust anonymization process, Publishing company can minimize the risk of potential data breaches or non-compliance penalties, translating to financial savings.
Conclusion
Snowflake provides a comprehensive solution to Publishing company’s need for data anonymization across its varied landscape. By offering a seamless integration with SAP and non-SAP systems, a user-friendly experience, a cost-effective pay-as-you-go model, and robust support for both on-premise and cloud solutions, Snowflake is well-positioned to meet Publishing company’s KPIs and provide a high return on investment. Additionally, Snowflake’s security features and dynamic data masking ensure that sensitive information is handled with the utmost care, aligning with Publishing company’s commitment to privacy and compliance.
EPI-Use Labs’s answer
DSM is designed as an add-on that is installed directly into each of the SAP systems in scope, removing any need for middleware and keeping execution logic ‘close to data’ for efficiency. DSM is a highly adaptable and user-friendly solution, ensuring seamless compatibility with both on-premise and cloud environments while guaranteeing significant reductions in costs and space requirements.
DSM itself doesn’t need much scaling in its architecture or design, but it is designed on principles that ensure it always takes minimum viable datasets and with excellent quality so that it can run in any size of SAP system from 100GB to 85TB+. It also scales well across system types, as shown by our wide range of supported systems and Industry Solutions.
Modularity and Extensibility are built into DSM. It is written in Object Oriented ABAP ensuring all coding is done to allow maximum extensibility, and the Business Object Workbench (BOW) provides a configurable and customizable-semantic layer for mapping and affecting data that means any customization is done at the data mapping level and inherited by every licensed function.
DSM provides a detailed Monitor Desk and extended “Trace” Options on every process.
Diagnostic Logs (DLs) are also captured for every run and can optionally be uploaded to our Client Central platform for analysis. It also provides a specific Audit Log to track the masking Policies.
EPI-USE Labs has been handling the export and import of SAP data for more than 25 years, providing security through data anonymization for the last 10 years within the Data Secure Solution. With the advent of GDPR, EPI-USE Labs redesigned Data Secure to allow full customization to specific requirements and enhanced coverage of the integrated SAP Data Model.
Leveraging the SAP domain knowledge already built inside the Data Sync Manager solution, we went one step further to map each individual Personally Identifiable data field within the standard SAP data model – then further integrated these fields with the relationships between SAP objects and the system. These have been collectively named the EPI-USE Labs Integrity Maps and with these, our solution understands both:
– An Employee can also be a Vendor/Customer and also be replicated to CRM/SRM as a Business Partner
– Functionally how the data interrelates both inside and ECC environment and between SAP systems
Building on these integrity maps with conditional rules to consider Individual ‘Person’ business Partners and groups/companies, we now provide a default policy covering all the master data you would expect, along with interpreted Cluster tables and linked transactional tables to ensure that when we anonymize a person in your SAP environment it is done without a trace of the original value and consistently throughout the solution.
During implementation, our Professional Services team will be able to work with Publishing company on the customizations required in order to make the specific changes for the Publishing company database. Our default policy and rules are detailed in this link where you will have access to view the document called ‘DSM Standard scrambling content scope.xlsx’.
Protect sensitive data
To mask sensitive SAP data, use pre-defined masking rules from our online user community, extend the rules if needed, and then apply them to scramble data during Syncs or in place.
Administrators can define masking policies in one place and apply them across the entire SAP landscape, thus masking all SAP systems consistently. Data Secure can even discover sensitive data in custom info types and protect it. The product handles large data volumes easily.
The standard delivery of Data Secure includes more than 2000 individual sensitive field mappings, collected into logical rules to deal with:
– Names
– Telephone number
– Email Address
– Banking information
– Company Car Registration
– Street Addresses and many more.
The spreadsheet called ‘DSM Standard scrambling content scope.xlsx’
will provide detail on the default rules and SAP objects which are covered out of the box by EPI-USE Labs. However, you will of course have customisations which you have implemented in SAP Z-tables and fields, as such the solution is fully extendable once the detailed requirements are understood. To help in identifying these requirements, we will support you in running a Data Discovery and Workshop as outlined below.
Discover your custom Personally Identifiable Information
Although EPI-USE Labs has extensive experience with multiple clients, we also know that each SAP instance is unique in what functionality will have been configured/activated and what has been customised. To identify Personally Identifiable information from the customised SAP solution, an EPI-USE Labs Professional Services Consultant will independently complete a Data Discovery within the SAP environment.
We leverage our unique, market-leading IP containing defined mapping of data throughout SAP ERP and its relationship with SAP CRM / SRM / SCM etc. contained in Integrity Maps (or IMAPS for short). These IMAPS are held as part of our full object definition for the SAP landscape and identify each data item and any linked data into a single grouping. We then combine this with our expert consulting services to search your SAP landscape for the Personally Identifiable Information (PII) data that may exist.
The Data Discovery will complete a search of the Data Element and Domain for each identified sensitive data item and report all areas of the client(s) which have shared data. The consulting team will then further analyze the connections and data contained to deliver a connected solution proposal and analysis of sensitive data exposure. To ensure these results are accurate, our consultants will need to perform the analysis against Production (or a very recent copy of Production) as the checks also confirm where data is populated, and therefore this also needs to be considered.
Transports containing our IP will be provided as part of the engagement. We will request that Publishing company imports these, and provides the relevant access for our consultants to complete the activity. The authorization to be provided must be in Production or a recent copy of Production and will mandatorily include the following (additions may be needed depending on the findings):
– Open Access to any table through SE16/N.
– Transactional access to /EUC/DS_DISCOVERY
(provided within the transport).
– Transaction to interrogate the data structures
through SE11.
– Job scheduling and monitoring through SM37, SM50
etc.
This is the absolute minimum access that is needed for the EPI-USE Labs consultant to be able to complete the technical discovery activity.The results of this analysis will be summarised into the Data Privacy Workshop and System Analysis Report. A default example of the output report has been shared along with this document, titled ‘Data Privacy System Analysis example.docx’. Link to access the document: additionnal info
Handling customisations in the delivery
In the preparation phase and in parallel to this RFP, EPI-USE Labs will ask Publishing company to execute the Data Sync Manager Readiness report in each SAP Abap Stack system involved. Within this report, there is a specific check for common Personally Identifiable information within your custom content. This will help us produce a ‘DSMr Privacy analysis summary.xlsx’ which will be shared and used for possible pricing
Although the identified fields may contain sensitive data, without a direct analysis and a requirement review for what Publishing company considers to be Personally Identifiable, it is not certain if this data should be in scope.
Following the workshop and detailed requirement definition a commercial review and change request process will be completed to finalise the amount of customisation which EPI-USE Labs will complete, and what Publishing company will complete themselves following training and standard Policy implementation.
Comply with data protection laws
Data Secure significantly reduces the risk of security breaches of non-production systems. It helps you comply with globally accepted data protection standards, such as Sarbanes Oxley and the General Data Protection Regulation (GDPR). This is crucial for the security of your employees, clients, and partners.
We propose to collaborate on this project with our esteemed partner, DATAPROF, a leading expert in data masking for non-SAP systems, and have independently provided their responses to this questionnaire. By leveraging the collective strengths of DATAPROF’s cutting-edge technology and our own expertise, we possess the full capability to meet Publishing company’s requirement for consistent test data masking across integrated SAP and non-SAP landscapes. In the following link, a webinar where we explain the cutting-edge approach employed by EPI-USE Labs and DATAPROF to effectively mask data across SAP and non-SAP landscapes.
https://www.youtube.com/watch?v=5nM1vNgRmpo Pricing options: Perpetual and Subscription. In order to provide prices to Publishing company, we need Sizing of the systems and run DSMr – The DSMr is a system assessment tool developed by EPI-USE Labs to help to assess your SAP landscape before you install one of our dsm solution and to estimate the cost of the project.
Baffle’s answer
Baffle’s data protection solution is well-equipped to address Publishing company’ data anonymization needs for their corporate non-production environments. Here’s how Baffle can fulfill their requirements based on the stated KPIs:
Efficiency and ease of use (KPI#1): Baffle offers a user-friendly Anonymizer tool that can seamlessly run on both SAP and Non-SAP systems. The tool is designed to simplify the data anonymization process, making it easy for Publishing company’ IT team to anonymize personal data across their diverse set of systems. The solution provides intuitive interfaces and workflows, ensuring a smooth and efficient anonymization process without the need for extensive technical expertise.
Compatibility with both on-premises and cloud solutions (KPI#3): Baffle’s data protection platform is designed to be agnostic to the underlying infrastructure. It supports both on-premise and cloud environments, including popular cloud service providers like Amazon Web Services (AWS), Microsoft Azure, and Google Cloud Platform (GCP). This compatibility ensures Publishing company can seamlessly deploy the anonymization solution across their hybrid IT landscape, covering a wide range of systems and databases without any compatibility issues.
High ROI and cost-effectiveness (KPI#2): Baffle’s data anonymization solution offers a high return on investment (ROI) due to its cost-effectiveness and comprehensive capabilities. By anonymizing sensitive data, Publishing company can significantly reduce the risk of data breaches and comply with data protection regulations, thereby avoiding potential legal and reputational costs. Additionally, Baffle’s solution is scalable, allowing Publishing company to pay for the exact resources they need, optimizing cost efficiency.
Furthermore, Baffle employs advanced cryptographic techniques such as format-preserving encryption and tokenization, ensuring that the anonymized data retains its referential integrity and usability for non-production purposes while still maintaining privacy and compliance. This means that development, testing, and other non-production teams can work with realistic, yet fully anonymized data, minimizing potential disruptions to business operations.
In summary, Baffle’s data protection solution meets Publishing company’ requirements by providing an efficient, easy-to-use Anonymizer tool that works across both SAP and Non-SAP systems. It ensures compatibility with on-premises and cloud environments, enabling seamless integration with their existing infrastructure. Moreover, Baffle offers a cost-effective approach to data anonymization, resulting in a high ROI, and helps Publishing company maintain compliance with data protection regulations, protecting their sensitive data from unauthorized access and potential breaches.
Libelle’s answer
Publishing company wants to anonymize test data on SAP and Non-SAP systems for GDPR-compliance and protection of sensitive data (e.g. trade secrets, salaries of board members). DataMasking anonymizes test data in a realistic manner and preserves consistency across an SAP landscape. DataMasking anonymizes irreversibly. Possible edge cases for testing purposes are preserved. DataMasking works on hybrid infrastructure: On-premises as well as cloud. DataMasking is available for ECC and S/4.
Arcad’s answer
The Publishing company problem we were presented with was the need to provide a service provider with anonymized data from production data on SAP and other DBMS. We understand, of course, that this anonymized data must remain fully consistent to be exploitable as if it were real production data. DOT-Anonymizer addresses this issue as follows:
1. Use of a unique “cache” technology that guarantees consistency between data from different anonymized databases. John Smith will always be anonymized as Peter Gordon, whether he comes from SAP or Oracle, from the vacation or employee table. If you choose, for example, to randomly change the gender, he may be anonymized as Silvia Durban, and his SS number in the anonymized databases will then begin with 2. In this way, the “usefulness” of the data is preserved.
2. Use of ready-to-use transformation algorithms such as data generation from directories, random generation, transformation of dates, addresses, IBANs, SS numbers, etc., which can be customized (groovy language).
3. Use of connectors with numerous DBMS, relational and unstructured databases, SAP, etc. A single tool to handle all your databases. 4. Automatic discovery of sensitive data in your tables. You automatically identify the fields to be anonymized according to the rules you have defined, and all that’s left to do is launch your transformation algorithm. DOT-Anonymizer enables you to provide your service provider with a consistent set of data, whether for testing, development or analysis purposes. You can restart the anonymization project at any time to provide updated data, on demand or on a scheduled basis.
Some of the personal data anonymization software responses are not published in this blog. Please contact@vektiq.com for more information.



